Building the ElevenLabs customer interview agent
Overview
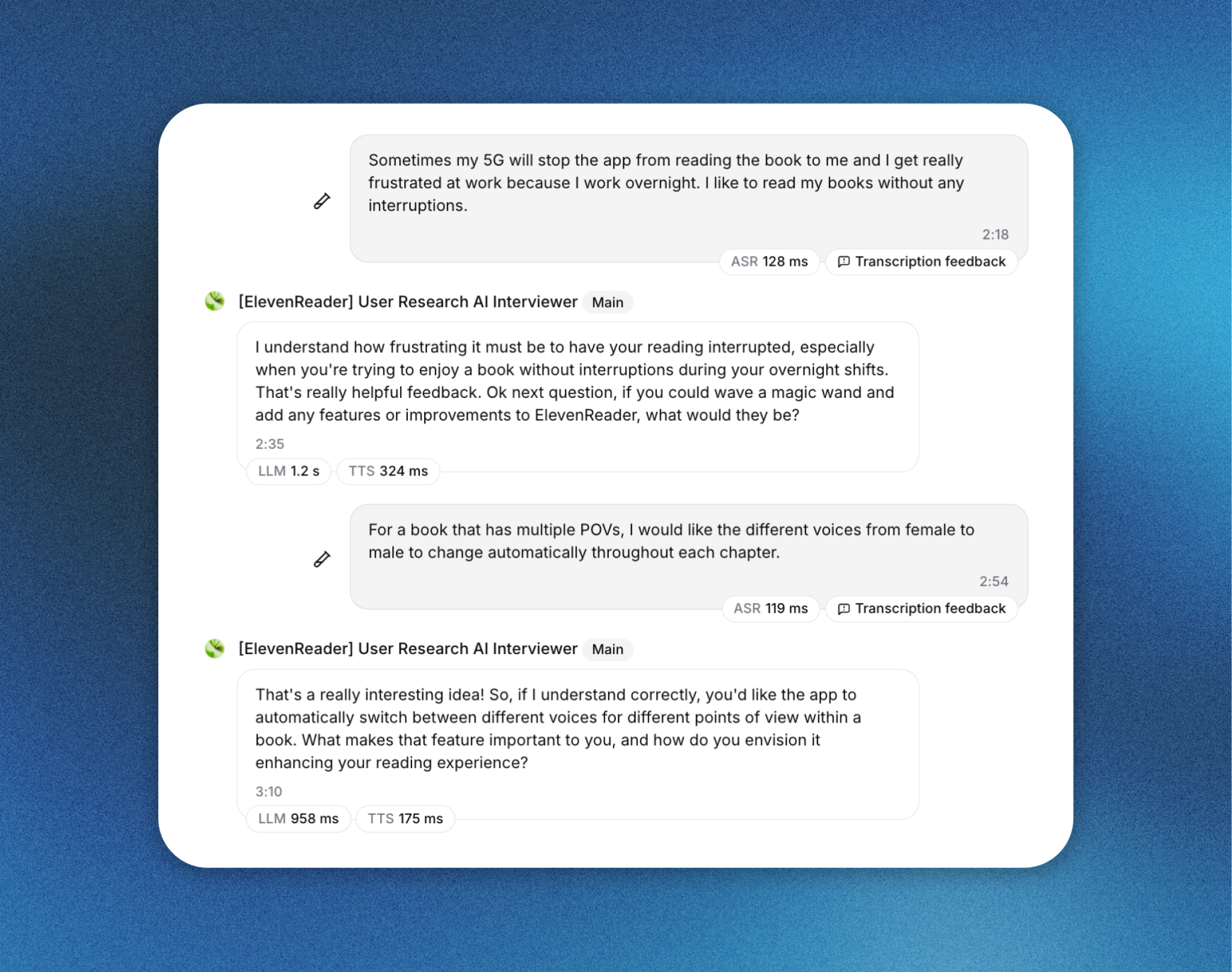
We built an AI interviewer using ElevenLabs Agents to collect qualitative user feedback for the ElevenReader app at scale. This document explains the system design, agent configuration, data collection pipeline, and evaluation framework we used to run more than 230 interviews in under 24 hours.
The goal was to replicate the depth and nuance of live customer interviews without the scheduling, language, and operational constraints of human-led sessions.
System architecture
The AI interviewer was implemented entirely on the ElevenLabs Agents platform, with the following high-level components:
- Conversational voice agent for real-time interviews
- Large language model for dialogue planning and reasoning
- Structured data extraction for post-call analysis
- Automated call termination and session control
Agent design
Research objectives
The agent was instructed to explore four primary research areas:
- Feature requests and product improvements
- Primary usage patterns
- Competitor comparisons
- Pricing perception and brand value
These objectives were embedded directly into the system prompt to ensure consistency across interviews.
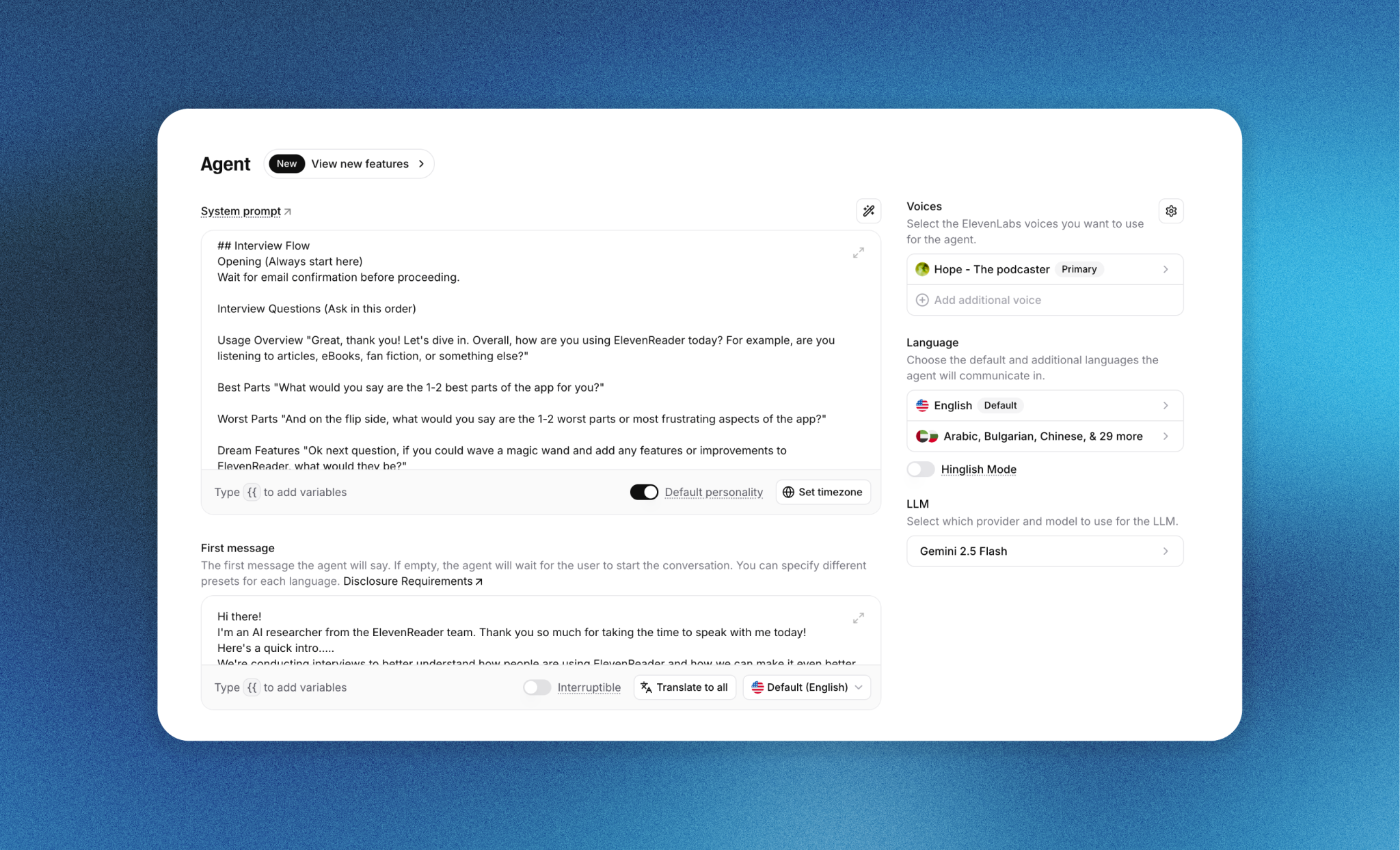
Voice selection
We selected the voice Hope - The podcaster for the interviewer. This voice was chosen for its neutral pacing, warmth, and conversational tone, which reduced perceived friction and helped users engage naturally over extended sessions.
Model selection
Reasoning model: Gemini 2.5 Flash
Gemini 2.5 Flash was selected to balance low latency with sufficient reasoning depth for adaptive follow-up questions during live conversations.
System prompt structure
The system prompt instructed the agent to:
- Ask open-ended questions aligned with research objectives
- Generate follow-up questions when responses were vague or minimal
- Avoid leading or biased phrasing
- Keep the conversation on topic and within a fixed time window
Following our prompting guide, here’s the complete system prompt we used:
Safety and edge case handling
Before production rollout, we ran simulated conversations using ElevenLabs testing tools to validate behavior for:
- One-word or non-informative responses
- Off-topic input
- Inappropriate language
- Silence or long pauses
These tests informed additional guardrails in the prompt to maintain interview quality.
Session duration control
Each interview was capped at ten minutes. The agent used the end_call tool to:
- Gracefully conclude the session
- Thank the user for their time
- Prevent excessively long or looping conversations
Data collection and analysis
Transcript processing
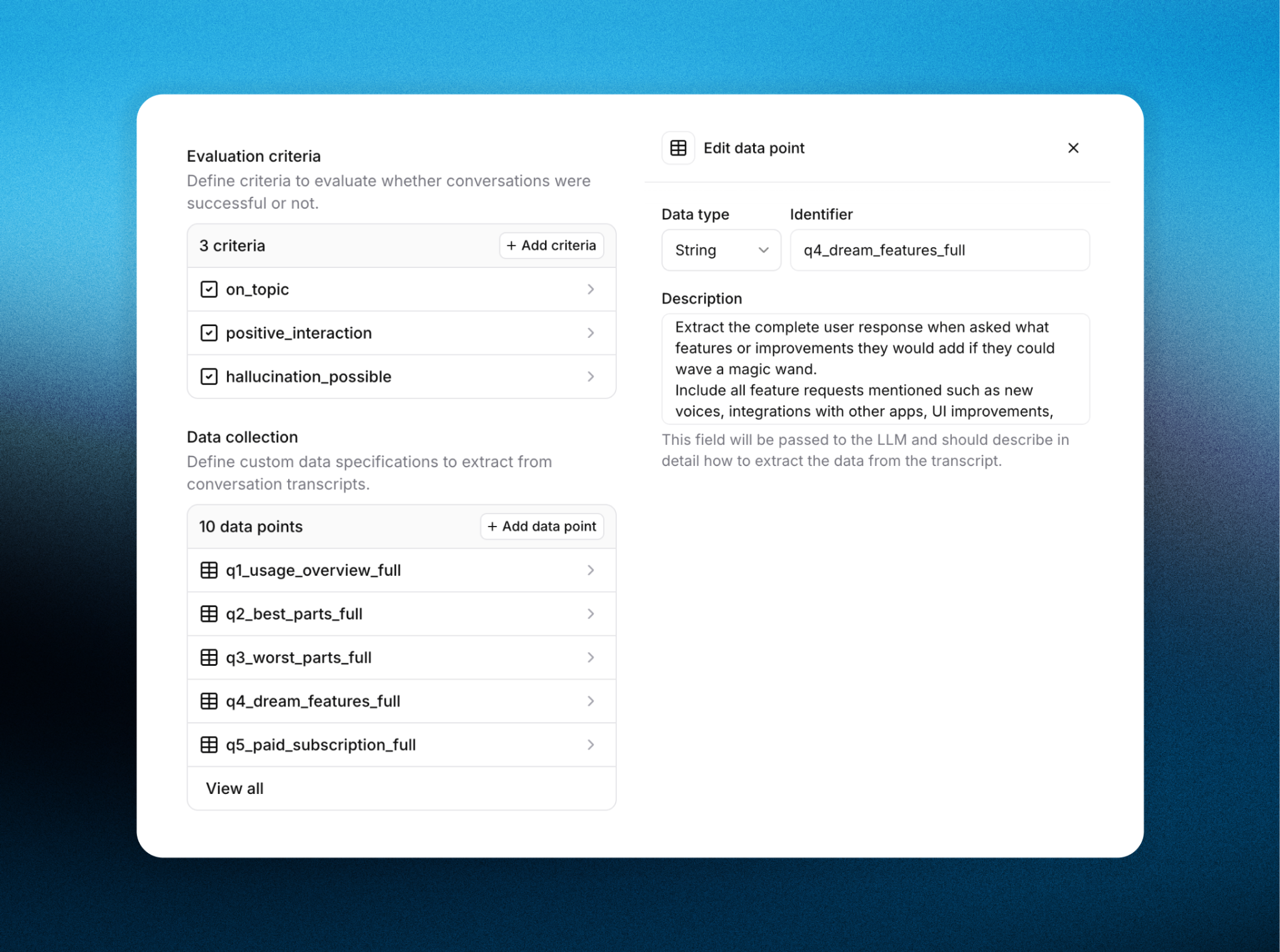
All conversations were transcribed and passed through the ElevenLabs Agents Analysis feature to extract structured data from open-ended dialogue.
We tracked responses to questions such as:
- “How are you primarily using ElevenReader today?”
- “What two changes would most improve the app?”
Structured outputs
Extracted fields included:
- Primary use case
- Requested features
- Reported bugs
- Sentiment indicators
This allowed us to aggregate qualitative feedback without manually reviewing every transcript.
Limitations and learnings
- AI interviews require careful prompt design to avoid shallow responses
- Time-boxing is essential to control cost and maintain focus
- Structured extraction is critical—transcripts alone do not scale for analysis
Future work
We plan to extend this system by:
- Adding adaptive interview paths based on user segment
- Integrating real-time sentiment scoring
- Expanding multilingual interview coverage
- Connecting extracted insights directly into product tracking systems
Start building your agent today or contact our team to learn more.